Why we chose a Monorepo
Some epic rivalries:
- Batman vs. Superman
- Right vs. Left
- Tabs vs. Spaces
- Monolith vs. Microservices vs. Monorepo
Monoliths, Microservices, & Monorepos
You want to get a stale, probably introverted nerdy software development team heated up? Ask them if they prefer tabs vs. spaces. Or maybe which programming language or IDE reigns supreme. One final debate that's sure to get the room stirring is whether you should build your project as a Monolith, with Microservices, or as a Monorepo.
To those who might not have heard these terms or concepts, or have but with limited detail and don't know exactly what they are, here's a short* break down:
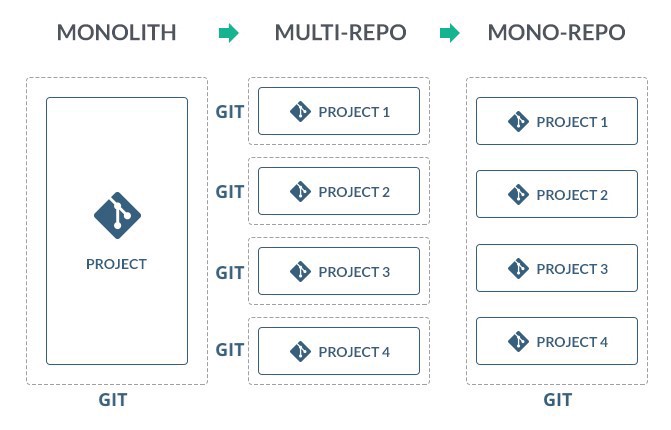
- Monolith: Think of this as a single codebase that is used to build all of the functionality that your product or business needs to get things done. You probably have a backend with a single API, a single frontend, and single test suite across the entire codebase regardless of how big or small it is.
- Microservice (multi-repo in the image below): A small codebase that does one thing, or a very small number of things well. Your business or product likely contains lots of small services like this, all of which focus on solving a very specific problem. A single microservice is likely a standalone API or something similar that has an easy interface to communicate with other services (HTTP, REST, GraphQL, etc.), and many times has its own standalone, segregated components separate from any other service (think database(s), caches, test suites, etc.)
- Monorepo (or mono-repo): A single repository that contains much, if not all of the code for a business or product to function, but that could be and likely is separated in some logical structure to separate services, apps, APIs, SDKs, or other codebases into their own little buckets inside the repo. You can likely
git clonethis repo and it will fetch all the code that exists for the business and/or product, but there are segregation of concerns based on the file structure inside.
90% Monolith
To start, there isn't a one size fits all answer as to which structure all projects should use. The answer depends on a lot of things like your use case, business, product/app design, etc. In saying that a large majority of products/projects/apps/etc. aren't revenue generating and/or don't make it past a few hundred or a few thousand concurrent users. What I'm about to say isn't data driven and I don't have any references to support this number other than anecdotal experience, but I would argue somewhere around 90% of projects never need to go beyond a Monolith.
You may be asking, “this article is written to advocate for Monorepos, why are you saying such a large percentage of projects simply need a Monolith?” That's a good point, but simply put a monolithic codebase frankly makes things easier. Having a single codebase where all your business logic lives and all your APIs use the same language and framework(s), authentication mechanism, middlewares, database(s), etc. will generally provide a quality of life improvement and save time. You can focus on solving your business problems and not spending a bunch of time scaffolding a new microservice and making decisions about mundane aspects like what programming language to use, what database(s) make the most sense, how to handle authentication, how to support communication to other services, what test suite to use, etc.
That being said, Monoliths can have several limitations and problems when a project becomes bigger and starts to scale in a relatively significant way. Here are a few scenarios that you might find yourself experiencing when it's time to start considering and making the move from Monolith to another architecture:
- Your successful app that is now scaling might have changing, more stringent performance improvements and your Ruby on Rails app isn't fast enough to consume and respond to thousands of requests per second in a reasonable time.
- Your development team has grown from two to ten people that make up two or three different teams and now when they're working on their tasks or projects you start to notice large merge conflicts taking more of their time to resolve when merging to the main branch.
- In a year you went from a few gigabytes of data to now approaching your first terabyte of data. Your single database is struggling to scale and keep query execution times to a reasonable and expected level (single to tens of milliseconds).
So...... Microservices? Monorepo?
Instead of talking through the pros and cons of Microservices and Monorepos to describe how you can structure your app(s), I'll walk through why and how a Monorepo has been such a success for Phalanx at risk3sixty and why we opted for it over Microservices.
Phase 1: Create our first microservice
A little over a year ago at the time of writing we had a Monolithic Node.js web app with a Vue frontend. We had several background jobs using node-resque and all of our data was stored in either a single Postgres or Redis database. The catalyst that triggered us to consider and ultimately separate a service into its own repo with its own dependencies, APIs, tests, etc. was due to the size of our Monolith and slow build/deploy time. We originally used ES6 and ES7 compliant Javascript throughout our app and babel to transpile it. We were starting to make a transition to Typescript as well, so our build chain was compiling ES7 Javascript to code that the currently-supported version of Node.js could run, Typescript files to Javascript, and a number of additional downstream tasks that would get our app ready to deploy. As you can imagine, as we built out business logic and APIs, the codebase grew and the amount of time it took to build took longer and longer.
The first service we broke out, what I'll call our image service, of the Monolith was a service that had puppeteer and sharp as dependencies and was a simple API that would take URLs to take screenshots of (using puppeteer) or convert images to the specification provided by the user (would support resizing images, changing colors, etc.) Obviously instead of just adding new API endpoints with the required code in our Monolith to support our use cases, we had to setup a new standalone repo, package.json file with all dependencies, web server, middlewares required, determine how to organize endpoints, etc. We also had to build out the library we would use to communicate with this new service from our original Monolith where the majority of our business logic existed since we could no longer simply import Dep from './dep' like we might have done previously.
While this process took a little more time than it would've to just add our APIs to our Monolith, ultimately once we were finished with the prototype we now had a new app that took a fraction of the time to build and run than it took our Monolith. That alone made a huge impact and we were satisfied with the result.
Great! Now let's run it all together
Awesome, we now have a Dockerfile and docker-compose.yml in our Monolith that starts our main app and all dependent databases and such in their own containers and a new Dockerfile and docker-compose-yml in our image service that runs it. Uh oh, how would we handle networking between different docker-compose environments? The best option is to have everything in the same single docker-compose.yml so we can name our services and subsequently setup our environment so all services can easily communicate between each other. But where would this new, aggregate docker-compose.yml file live?
Monorepo it is
The way we solved this was to instead restructure our main codebase to add some language namespaces, cmd vs pkg directories here to distinguish between standalone apps and libraries/SDKs, and finally individual repositories. At this point we can create a root docker-compose.yml and add all Dockerfile contexts based on the service(s) we need to include, and easily combine our original Monolith web app with our new image service. This worked great and we were up and running both services and able to communicate between both with little headache.
Our directory structure for our Monorepo was as follows after adding a couple SDKs, libraries, and beginning a Go API.
phalanx/
├── .circleci/
│ └── config.yml
├── nodejs/
│ ├── cmd/
| | ├── img-service
| | └── phalanx
| ├── pkg/
| | ├── phalanx-node-sdk
| | └── phalanx-utilities
├── go/
│ ├── cmd/
| | └── phalanx-go-api
│ └── pkg/
| | └── phalanx-go-sdk
├── docker-compose.yml
└── README.md
Conclusion
I'll reiterate again that there is no one size fits all solution to how to structure your project(s). The answer depends on a number of factors from size and scalability needs to what you're comfortable with as a developer. Our Monorepo experience has been outstanding so far and we now have ~20 different packages, libraries, apps, and APIs within our Monorepo that are painless to make changes to, add features, run tests, and deploy.
Not only is the R&D experience nice, but we can setup CI to only run tests within the repo(s) we're working on, so you're not running all tests in the entire set of apps on each deploy, just the ones you want or that have changed. Finally, teams can own their own apps or libraries and you're almost never going to cause merge conflicts with the main branch against other teams codebases even though you're technically working in the same repo.
As you scale your business and apps, I highly recommend looking into this structure as it supports rapid prototyping and development and keeps things clean and scalable so you can focus on the business problems your solving!